AI Custom GPT Chatbot
In spring 2023, my friend Philippe came to me with a startup idea and asked if I was interested in taking part. Our skills meshed well together -- he was a machine learning engineer and my expertise was in building UIs.
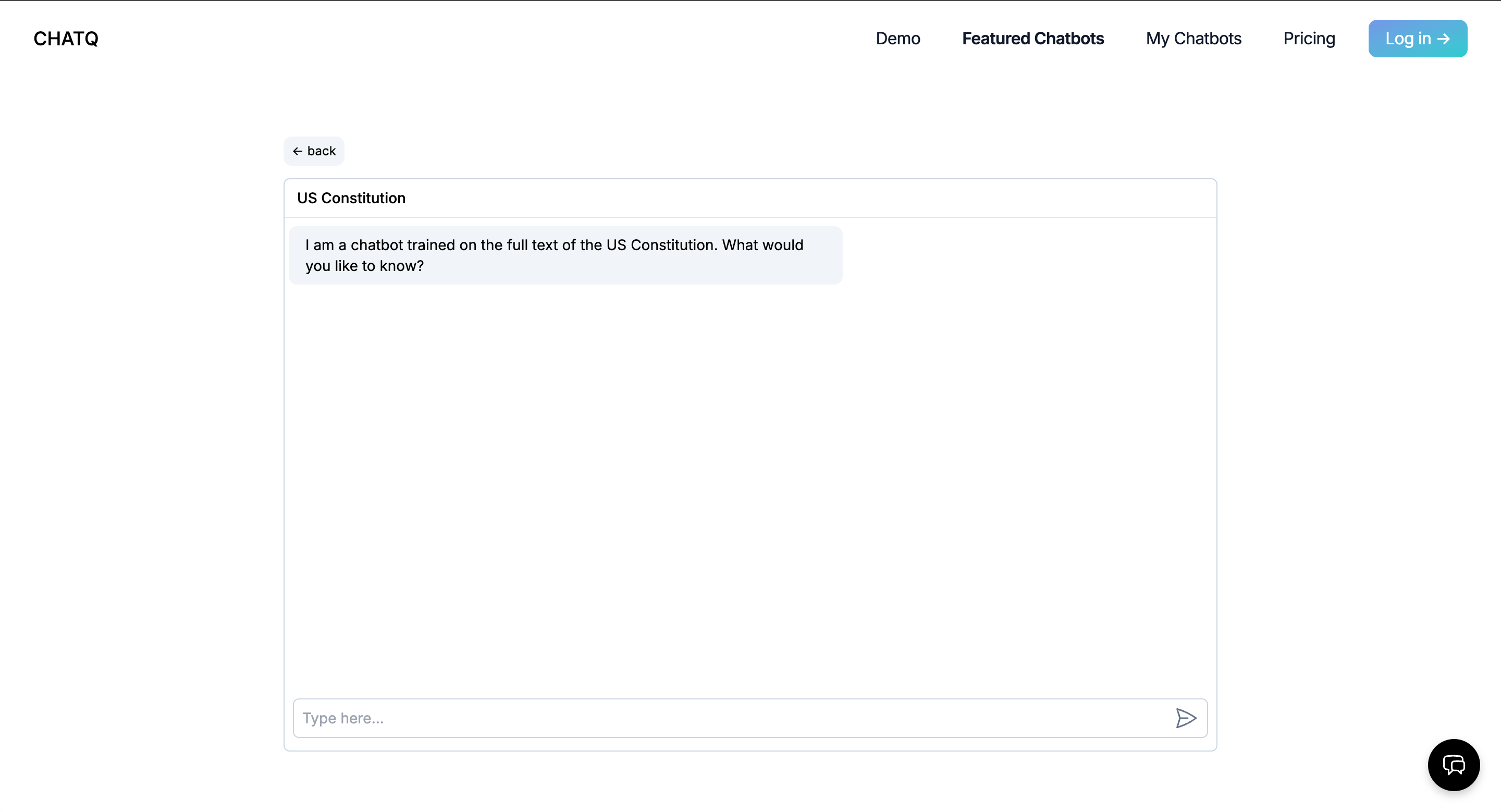
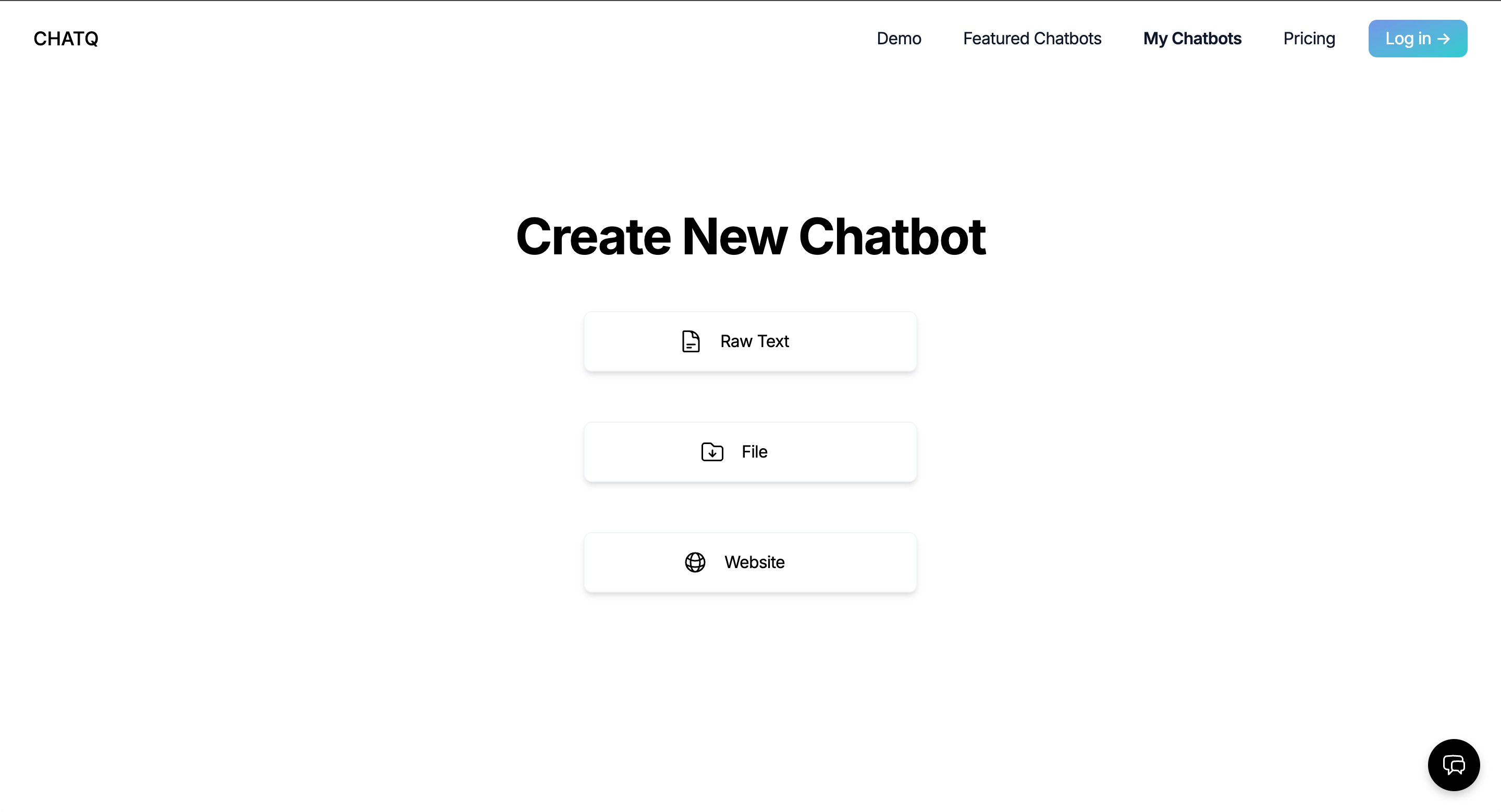
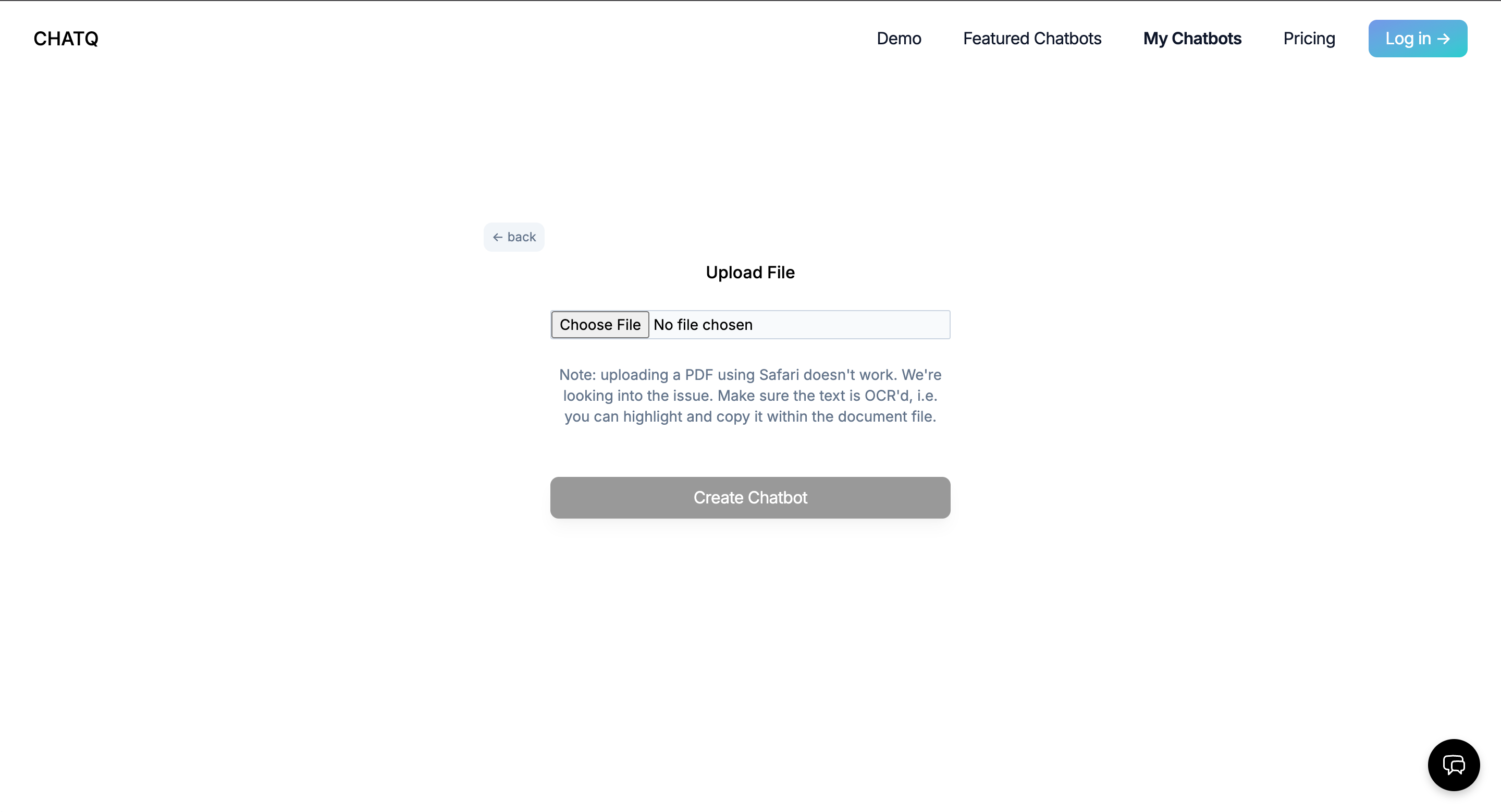
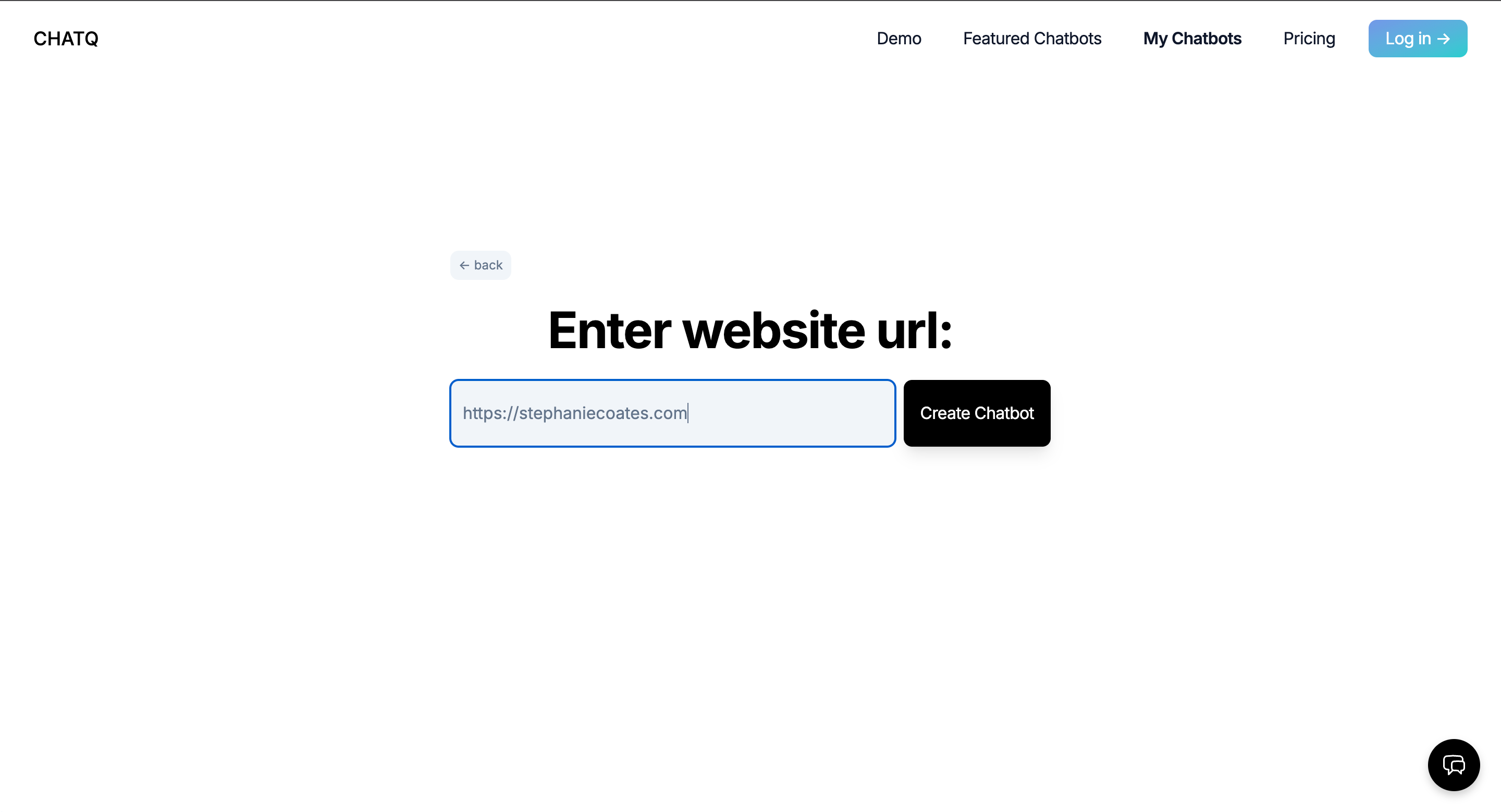
Together we built ChatQ, a chatbot product modeled on OpenAI's chatgpt-retrieval-plugin, building on top of ChatGPT but adding the ability to fetch and integrate relevant information from custom documents or data sources. Instead of just relying on the latest LLM's trained knowledge, our product allowed the user to build custom chatbots that integrated domain-specific, proprietary, or simply more recent information into its dataset through document upload, web scraping, or raw text submission.
Sound familiar?
In November 2023, during their Dev Day event, OpenAI released GPTs, enabling users and developers to create custom GPTs tailored for specific tasks by incorporating their own instructions, files, APIs, and more, all on the ChatGPT platform. This is known as Retrieval-Augmented Generation, or RAG.
Our project got squashed by the big guns. I remember Sam Altman speaking about this concept on a podcast -- he advised that startups should focus on creating products that benefit from improvements in large AI models rather than attempting to compete with big tech companies that are developing those models. Though we weren't trying to train our own model, in retrospect, it was inevitable that that big companies would integrate this RAG technology directly on their platforms.
We laid ChatQ to rest and Philippe pivoted to work on another startup idea. Even though we aren't maintaining the project, It was still a great learning experience and piqued my interest in the fast-moving AI landscape.
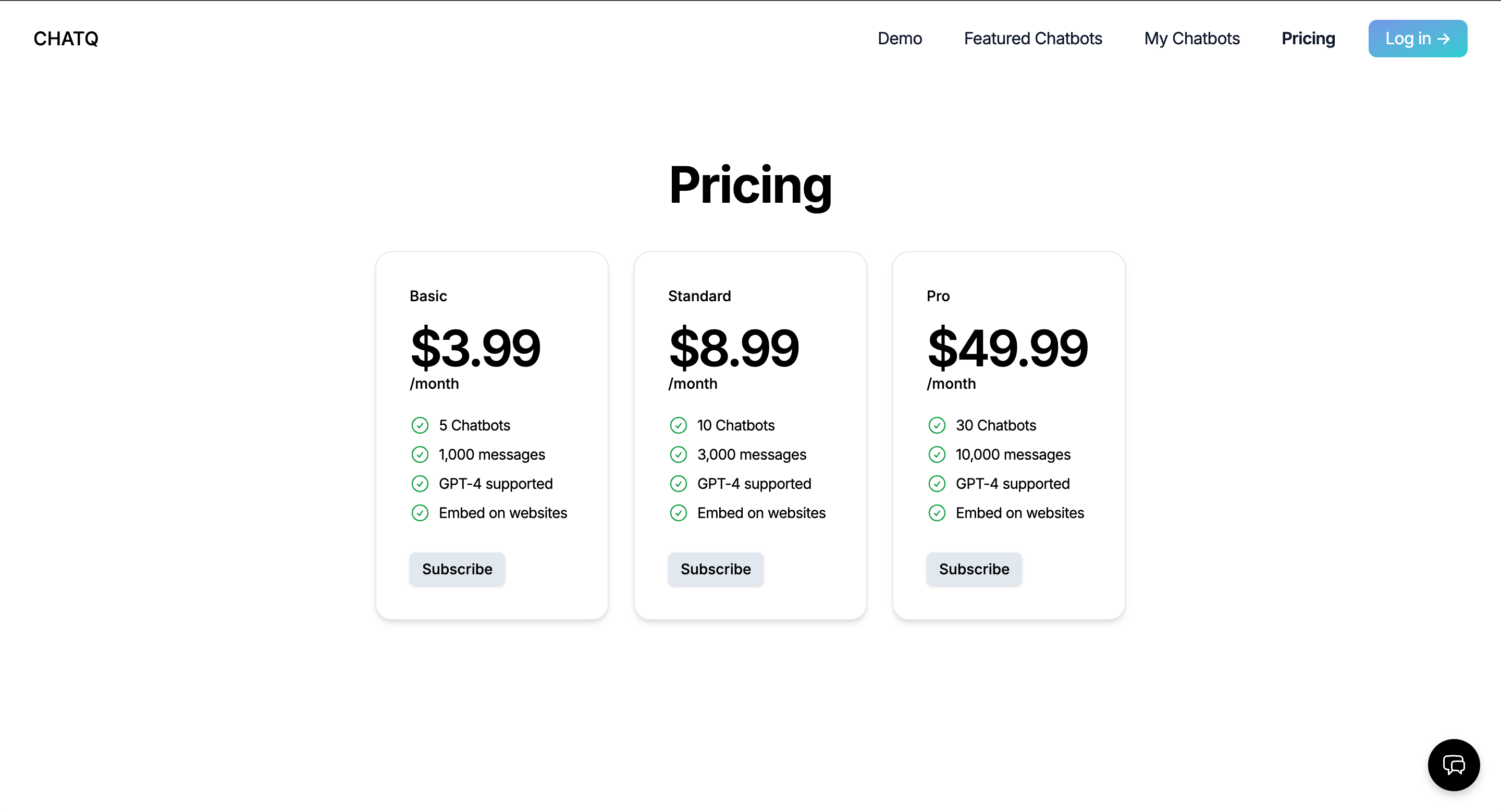
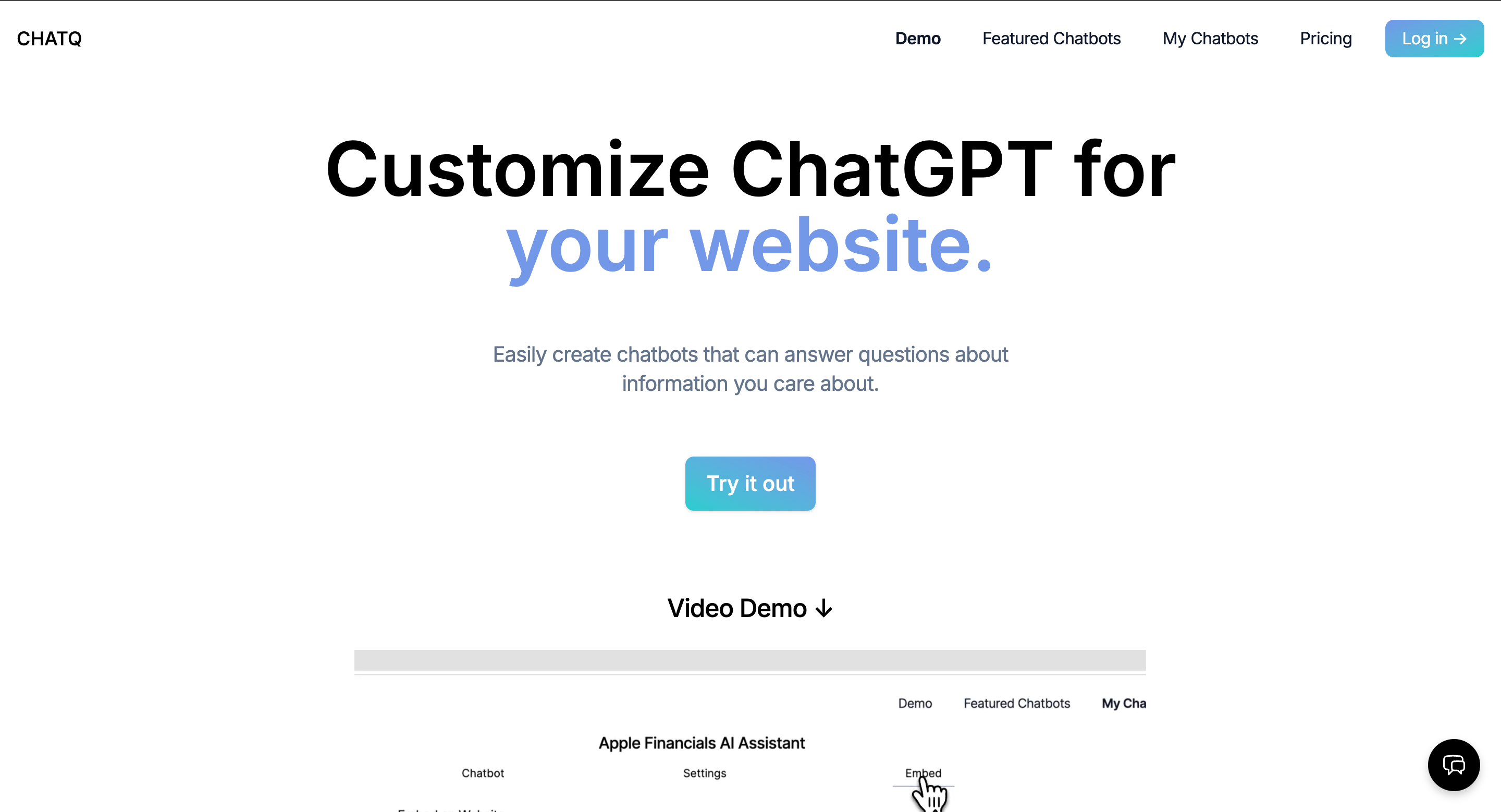
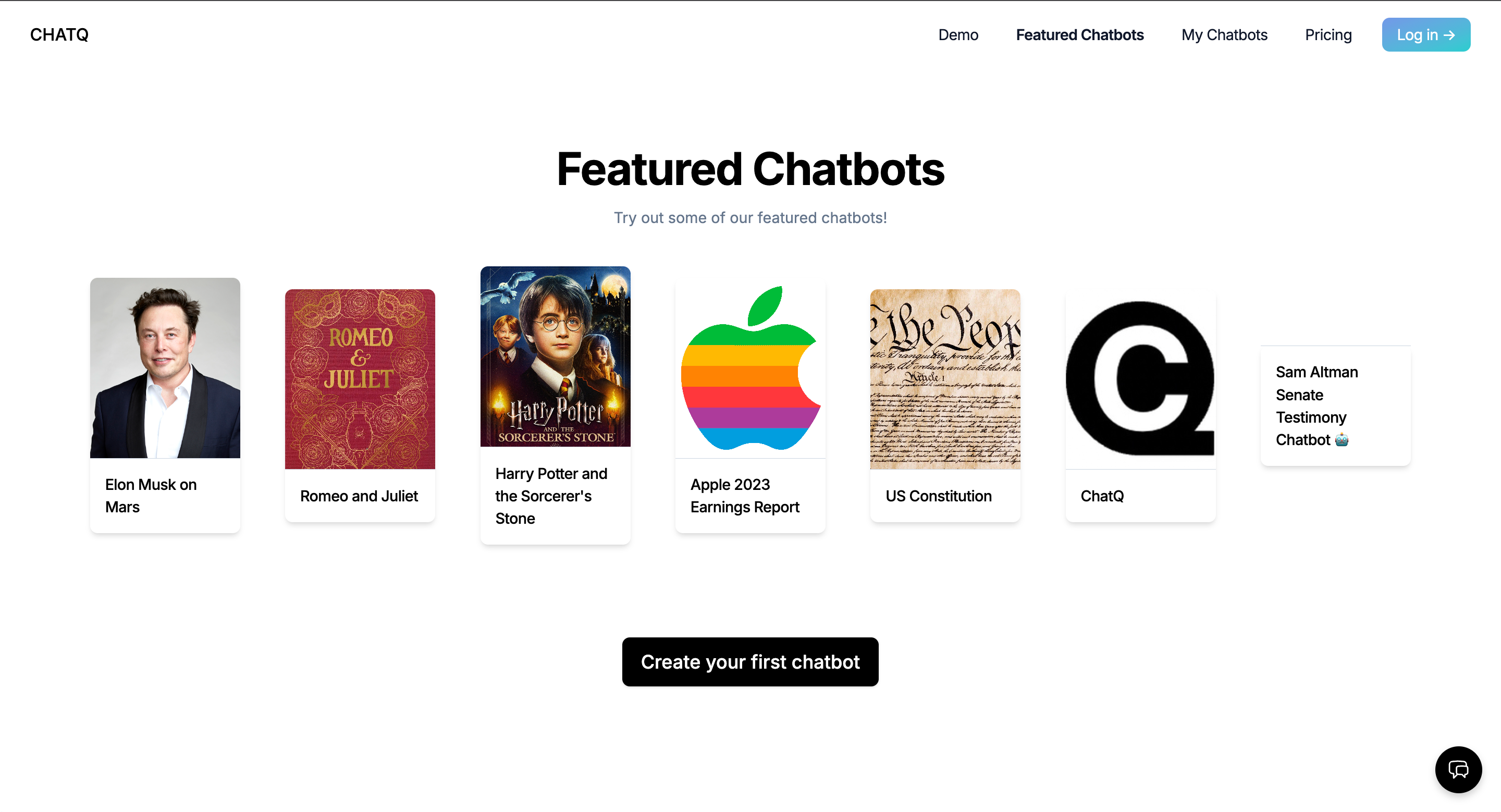
The project nuts and bolts:
- Frontend built with Typescript, React, and TailwindCSS
- Web server built in Python
- Prompt queries and custom documents fed into an OpenAI embeddings model (text-embedding-3-large) to generate numerical representations of the content
- Embeddings stored and indexed in Pinecone vector database
- Hosting, user authentication and authorization, and additional application data storage on Firebase
How it works under the hood:
- Within the app UI, a user uploads a custom document, website to scrape, or raw text they want their custom chatbot trained on.
- The custom content is fed into the embeddings model to generate embeddings of the content chunks, which are then stored and indexed in the Pinecone vector DB.
- When a user prompts their custom chatbot, the prompt is converted into an embedding and sent as a query to Pinecone. Pinecone performs a similarity search to find relevant chunks from the pre-uploaded custom content. These chunks provide the specific details and context that a pre-trained LLM wouldn't have access to.
- The original prompt and returned content chunks from the vector database are then passed into the ChatGPT LLM via the OpenAI API.
- ChatGPT generates a response by incorporating both general knowledge from the LLM as well as retrieved context from Pinecone, resulting in more accurate answers customized to the user's uploaded content.